1. Connecting to a Server#
This chapter will show you how to connect to a server using the SSH (“secure shell”) protocol, how to interact with that server through a remote shell, and how to move data and code between your local computer, the Internet, and the server. Along the way, you will learn about how SSH proves your identity to a server, how to configure your local computer to make using SSH more comfortable, and about basic server etiquette.
Learning Goals
Learn how to connect to a remote server using the SSH protocol
Learn how to peacefully co-exist with other users on the same server
Learn about passwords and SSH keys
Learn how to move data between your local PC, the Internet, and a server using
wget/curl,sftp, andscpLearn about the POSIX directory structure and access permissions
1.1. What Is a Server?#
A server is a computer that can be accessed over a network—typically the Internet. More specifically, a computing server is one that gives users access to a remote command line where they can run programs on that server. Servers typically provide more memory, more disk space, and faster processing units than a personal computer, and can therefore work on bigger problems.
Unlike users’ personal computers, servers typically run some Unix-like operating system, which in almost all cases is Linux; they are typically controlled primarily via the command line; they are typically shared by multiple users, often at the same time; and they are operated and maintained by dedicated staff, called system administrators or system operators (SysAdmins or SysOps for short).
1.2. How to Connect to a Server#
You can connect to most computing servers using the secure shell protocol (SSH). The “secure” in secure shell means that all messages sent between your local computer and the remote server are encrypted. This makes it practically impossible for a third party (anybody besides you and the server’s administrators) to see what’s sent over the connection.
In order to connect to a server over SSH, you first need to have an account on that server. To get an account, you typically have to fill in an online request form or contact a system administrator, and then wait for your request to be approved. Assuming it is, you’ll be given an account name and some way to prove, or authenticate, your identity to the server. In the SSH protocol, there are two main authentication methods: passwords and SSH keys. We will discuss both in detail in Section 1.4.
Tip
If you’re affiliated with UC Davis, you can request accounts on the university’s high-performance computing clusters (collections of servers) through HiPPO, the High Performance Personnel Onboarding website.
1.2.1. Opening a Connection#
Once you’ve obtained an account on a server and a way to authenticate yourself, you can log in to the server using SSH with the command
ssh <account name>@<server name>
where <account name> is the name of the account on the server that was
assigned to you, and <server name> is the Internet host name or IP address of
the server. This command establishes a connection between your computer and the
server, and starts a new shell session on the server.
Caution
You’ve likely seen the @ notation before in email addresses, but the account
and server names will not necessarily match your email address.
The command might ask for a password, which will be the one given to you by the server’s administrator, not the password for your local computer.
Important
It might look like nothing is happening as you type your password, because in the command line, characters in a password typically aren’t printed. But never fear, the command line is still paying attention to what you type.
So: keep calm, type your password, and press Enter!
Note
For the remainder of this chapter, we’ll use “SSH” to refer to the SSH
protocol—that is, the language spoken between a local computer and a server
to establish and maintain secure connections—and ssh to refer to the
command line program that implements the client side of the SSH protocol.
After the SSH connection has been
established, anything you type into the terminal from which the ssh command
was run will be forwarded to the shell on the remote server, and any output
from that remote shell, or from programs run within it, will be forwarded to,
and printed by, the terminal on your local computer. In other words, you can
interact with the remote shell running on the remote server in the same way as
with the local shell on your local computer, but any commands executed in that
remote shell will be run on the remote server. Finally, when you shut down the
remote shell, for example by entering the exit command, the SSH connection
will be closed, and the terminal on your local computer will control your local
shell again.
Note
An alternative formulation of the log in command is:
ssh -l <account name> <server name>
The -l flag informs ssh that the account name is provided separately.
A brief SSH session might proceed like this:
me@mypc$ ssh testuser@testserver
testuser@testserver's password: ************
Last login: Mon Dec 4 12:00:59 2023 from 192.168.2.109
testuser@testserver$ date
Tue Dec 5 09:03:13 PST 2023
testuser@testserver$ ls ~
src data Documents Downloads Temp ToDoList.txt
testuser@testserver$ exit
logout
Connection to testserver closed.
These are the steps of the above example in detail:
You run the
sshclient program in a terminal on your local computer, providing the name of the server to which to connect and the name of the account into which to log in.The
sshprogram prompts you to enter the password associated with your account on the server (assuming that the account was set up to authenticate via a password, more on that below).You enter the (correct) password, which is not echoed back for security reasons.
The server prints some welcome message indicating that the SSH session has been established. On this particular server, the message contains the last time at which you have logged into the server. This can help to detect if your account has been compromised and has been accessed by someone impersonating you.
You run the
datecommand on the server, which will print the server’s current time. The server might be in a different time zone than you, or its clock might be slightly offset compared to your local computer’s clock, meaning that it might display a different time than you would expect.You run the
ls ~command, which lists the contents of your home directory on the server, not the one on your local computer.You run the
exitcommand on the server, which will terminate the remote shell, close the SSH session, and return control to the shell running on your local computer.
Most importantly, both the date and ls ~ commands were run on the
server, not on your local computer. Only the output from those
commands was forwarded from the server to your local computer over the SSH
connection, and then printed in your local computer’s terminal.
Tip
There is a second way to use ssh to quickly execute a single command on a
remote server without entering an interactive shell. You do this by appending
the command line that should be executed on the remote server to the ssh
command itself, like so:
me@mypc$ ssh testuser@testserver date
testuser@testserver's password:
Tue Dec 5 09:10:14 PST 2023
This example connected to the same account on the same server as before,
executed the date command on the server to print the server’s current time,
and then immediately closed the SSH connection and returned control to your
local computer. This is a good way to quickly run a small command on a remote
server, or to run remote server commands from scripts.
1.3. Basic Server Etiquette#
Unlike most personal computers, servers are typically shared resources. This not only means that a single server can have multiple user accounts that belong to different people, but it often means that there are multiple users connected to the same server simultaneously, all running programs and using the server’s resources at the same time. All users should therefore follow etiquette to ensure that no single user “hogs” a server’s resources to the point that it unduly interferes with other users’ work, that users don’t invade each others’ privacy, and that the relationship between users and server administrators remains amicable.
1.3.1. Resource Use#
Server resources broadly fall into four categories:
Computing bandwidth: While servers are typically designed for heavy computation, they do contain a finite number of CPUs (and/or GPUs) that can execute a finite number of operations per second. If the total requested computing bandwidth, i.e., number of requested operations per time unit, exceeds the existing bandwidth, computation will slow down proportionally for everyone.
Memory: While servers typically have a lot of memory, it is, again, a finite resource, and if the total memory requested by all active users exceeds existing memory, there will again be slow-downs. Memory related slow-downs, however, typically have vastly worse effects than computing-related slow-downs. If the total requested computing bandwidth exceeds available bandwidth by a factor of X, every individual computation will roughly slow down by a factor of X. If available memory is exceeded, on the other hand, the operating system will respond by “swapping” memory to and from the server’s hard drives, which is several orders of magnitude slower than system memory, and excessive swapping can grind even a very powerful server to a virtual stand-still. It is therefore crucial that users be mindful of the memory requirements of the jobs they submit to a server.
Storage space: While again much larger than the storage space available on typical personal computers, this resource has a hard limit. Once a server’s hard drives are full, they are full, and no further data can be written to them. This will usually crash running operations of all active users, not just those started by the user who filled the hard drive, and thus cause significant losses. To avoid this critical problem, servers typically limit the amount of hard drive space available to each user such that total usage can never exceed available space, meaning that if a user’s program tries to use more than available hard drive space, only that user’s program crashes. Regardless, all users should be mindful of the amount of hard drive space their submitted jobs require.
Storage bandwidth: Writing data to or reading data from hard drives is several orders of magnitude slower than writing or reading data from memory. If the total hard drive bandwidth requested by all active users exceeds existing bandwidth, hard drive operations will slow down proportionally for all users. Different servers may have different policies regarding hard drive bandwidth. For example, a server may have a special hard drive set aside for reading/writing large amounts of temporary “scratch” data, and another for long-term storage of large files. All users should be aware of any special policies that apply to the servers to which they connect.
The later chapters of this reader will introduce strategies to estimate the resource needs of a particular operation before running the operation, to be able to plan ahead and ideally coordinate with a server’s administrators before submitting an exceedingly resource-intensive job.
1.3.2. Job Scheduling#
To ensure smooth operation and fair allocation of the above resources, many servers implement job scheduling systems that let users submit operations they want to run ahead of time, and then select which jobs to run in which order to maximize total performance and minimize slow-downs due to contention.
Section 3 describes Slurm, a popular scheduling system, in detail. The main take-home message here is that you should not start some job that requires large amounts of server resources simply by logging in to a remote server and immediately running a computation command from that server’s shell.
1.3.3. Cluster Computing#
The above note is especially important for clusters, which are groups of interconnected computers that act as a single server. Clusters are typically organized such that there is a single so-called head node that manages the operation of the entire cluster, and a large number of computing nodes (dozens to thousands) that actually run the computations requested by users. When a user submits a job to a remote cluster, the head node will subsequently send that job to one or more computation nodes, ideally ones that are not currently used by anyone else, so that the job can run with minimal interference and finish in the shortest amount of time possible.
This architecture creates a potential issue: when you log into a remote cluster via SSH, you typically connect to the head node. But the head node is only meant for two purposes: to upload or download data or programs to/from the cluster, and to schedule jobs for execution on the computing nodes using some job scheduling system. Meaning, if you start a computation on the head node by directly running some command from the remote shell, you could easily overtax the head node’s resources and bring the entire cluster to a halt. Do not do this.
Note
According to the system administrators, on UC Davis high-performance computing clusters, it’s okay to compile and/or install software on the head node.
Of course, after you’ve installed the software you need, make sure to run your actual analyses on computing nodes!
1.3.4. User Privacy#
A second component of server etiquette is user separation and privacy. Users
store their private programs and data in their respective home directories,
which can be found in the /home directory hierarchy as /home/<account name>. While home directories are typically shielded from other users via
access privileges, this shielding is not always perfect, and it is considered
extremely rude to poke around in accidentally mis-configured home directories
belonging to other users. The same holds for inspecting files belonging to
individual users that might appear outside of their home directories, for
example in the /tmp temporary storage directory.
1.3.5. Administrators Are People#
Finally, users should always remember that computing servers, especially in the scientific computing context, are operated and maintained by real people, not faceless cogs in some giant machine. It is therefore always a good idea to treat system administrators or other IT support staff in the same way as one would like to be treated by them:
Users should know and follow any policies associated with each server they are using. This includes things as which job scheduling systems to use, where to store large temporary or permanent files, limits on resource usage, etc.
Users should make an honest effort to try and fix problems they run into on their own, for example by searching for solutions to their problems on the Internet or on a server’s support web site, before directly contacting administrators or IT support for help.
Users should remember that administrators and support staff are often overworked, and might not be able to respond to questions or to fix problems on a moment’s notice. It is always a good idea to plan ahead to ensure that a problem with a server, should it occur, does not occur five minutes before an important deadline.
1.4. SSH Authentication#
The SSH protocol provides two main ways of authenticating that you are who you claim to be and that you have the right to connect to a server: passwords and SSH keys.
1.4.1. Passwords#
For some servers, you can use a password to establish your identity. The process is very similar to the way you use passwords log in to your computer or to access websites and services such as Google Drive and your email.
Server passwords are not managed by the SSH protocol itself. They are, in fact, standard passwords in the server’s operating system (typically Linux) and are managed by that operating system. This means they follow the same rules as standard passwords and have the same drawbacks and caveats.
Caution
When you use a password with a website or service, they have to store a record of your password. Their security could be breached—and your password leaked or stolen—at any time.
SSH keys, described in Section 1.4.2, are safer than passwords, because no private information is stored on the server. The equivalent for websites is passkeys.
Some servers do not allow password authentication because the administrators do not want to take on the security risk.
Tip
Use a different password for each account to minimize the risk of a malicious person gaining access to them. You can use a password manager to help you choose strong passwords and eliminate the need to remember all of them.
The webcomic xkcd also provides some sound and practical advice on how to choose strong passwords:
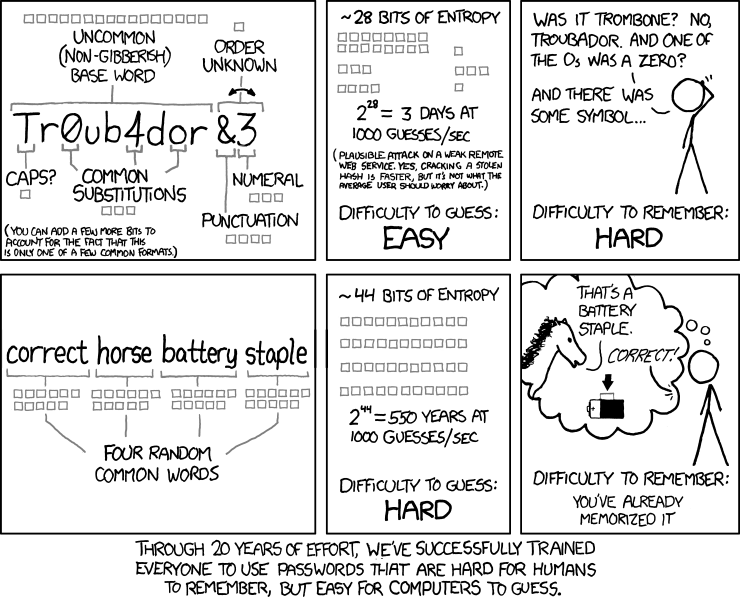
Fig. 1.1 “Password Strength” from “xkcd” by Randall Munroe (license).#
When you sign up for an account on a server that allows password authentication, the server’s administrators will typically assign you some initial random password and communicate it to you through an insecure channel like email. You should and are expected to change this initial password the first time you log in to the server.
To change your password, log in to the server and then run the passwd
command. Here’s an example of what going through these steps in a terminal
looks like:
me@mypc$ ssh testuser@testserver
testuser@testserver's password:
Last login: Tue Dec 5 09:02:20 2023 from 192.168.2.109
testuser@testserver$ passwd
Changing password for user testuser.
Current password:
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
The passwd command will first ask for your current password, that is, the
initial password that was assigned to you. The command will then ask for a new
password and check that password against its internal password rules, whatever
they may be.
If the new password satisfies the rules, the command will ask you to enter the
password a second time to confirm. After you enter the password again, the
passwd command will print a confirmation message and immediately activate the
new password. This means you must use the new password next time the server
asks for your password, such as the next time you log in.
If, on the other hand, something went wrong, passwd will print an error
message like this:
passwd: Authentication token manipulation error
The command will not activate the new password, meaning that you must
continue to use the old password, whether to log into the server or to attempt
to change the password using passwd again.
Note
The passwd command changes passwords on computers with Unix-like operating
systems, whether or not the computer is a server. You can use it to change your
server passwords because server passwords are just standard operating system
passwords.
Note
There is a slight variation of the password authentication method, where your account on a computing server is tied to another account that you already have. For example, a computing server managed by a university might use your existing campus-wide IT account to authenticate you. In that case, you just log into the server with your usual account name and password, and you don’t change your password on the server (in fact, it might not even be possible to do so).
1.4.2. SSH Keys#
You can establish your identity with an SSH key, a kind of cryptographic key. An SSH key consists of two separate key files:
A public key file which can be used to encrypt data. The public key is meant to be freely shared, so that people (or servers) can encrypt data they want to securely send to you.
A private key file which can be used to decrypt data that was encrypted with the associated public key. The private key is meant for you alone, so that only you can decrypt and use data that people send to you.
Unlike passwords, private keys are exclusively your property, and should never be shared with anyone else. SSH keys are much more secure than passwords, to the point that many servers only allow SSH key authentication. An additional benefit of SSH keys is that they make connecting to a server or cloud service like GitHub seamless—you no longer have to enter a password.
Note
SSH keys are an example of an asymmetric cryptography scheme, and are often based on the Rivest–Shamir–Adleman (RSA) algorithm, which is a super interesting topic for another day.
Before you can use an SSH key for authentication with a server, you must first send the public key to the server’s administrators, so that they can associate it with your account. You can usually do this through an online form or via email.
When you attempt to connect to a server over SSH and use an SSH key to
authenticate, the server encrypts a message with your public key and sends it
to your computer. The ssh program on your computer then decrypts the message
with your private key and responds to the server with proof that the message
was correctly decrypted. This proves to the server that you have the private
key, and thus that you are who you claim to be. Crucially, your private key
never leaves your computer during this exchange, so it can’t be stolen by a
malicious third party.
From a practical perspective, key-based authentication has a number of important differences in comparison to password-based authentication:
Public keys can be freely shared with anyone, without concern. They can be sent via email, posted on websites, or published in books.
Private keys must not be shared with anyone. They should only exist on your computer(s). Importantly, they are not shared with servers you connect to via SSH.
It’s relatively safe to use the same SSH key for any number of different servers. Even if one server gets hacked, the information that hackers could potentially glean would not allow them to log into any of your accounts on other servers.
Danger
Private keys must be kept private.
SSH keys are only as secure as the computer on which you store them. If your computer gets stolen or hacked, thieves or hackers could potentially gain access to your accounts on all servers for which you have SSH keys, unless the keys themselves are protected by strong passphrases.
NEVER EVER AT ABSOLUTELY NO TIME GIVE ANYONE YOUR PRIVATE SSH KEY EVER!
If an SSH key is protected by a strong passphrase, it is practically impossible for a hacker to use, even if they’re able to access the private key files on your computer.
NEVER EVER AT ABSOLUTELY NO TIME GIVE ANYONE YOUR SSH KEY PASSPHRASE EVER!
1.4.2.1. Creating SSH Keys#
To create an SSH key, open a terminal on your local computer. Then run the
ssh-keygen command:
ssh-keygen
Generating public/private ed25519 key pair.
Enter file in which to save the key (/home/me/.ssh/id_ed25519): new_key
Enter passphrase for "new_key" (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in new_key
Your public key has been saved in new_key.pub
The key fingerprint is:
SHA256:H7pntDdIbIlSJ7GaTzI83O4SSCcNtyg5X4wNX6ZmqF8 me@mypc
The key's randomart image is:
+--[ED25519 256]--+
| |
| o . + |
| . % = o |
| + * % + . |
| * X =S=.. |
| . o E +o*. |
| . . X.+.o |
| . . o.= o |
| ooo . . |
+----[SHA256]-----+
First ssh-keygen will prompt you for two pieces of information:
A file in which to save the private key. The default is a file named
id_TYPE, whereTYPEis the type of cryptographic key, in a hidden.ssh/directory in your home directory. Enter a path to specify the file, or leave this blank to accept the default. The default is usually fine unless you want to maintain multiple keys (more on that below).An optional passphrase to protect the new private key. As mentioned above, it’s crucial to keep your private key private and safe. As such, it’s a good idea to set a passphrase for the key. Most operating systems can be configured so that you only have to enter the passphrase the first time you use the key in a given computing session.
Then ssh-keygen will generate the key and print out some information:
The file where the command saved the private key. Never share this file with anyone.
The file where the command saved the public key. This is just the path to the private key with
.pubappended to it. You can safely share this file with others.The new key’s hash fingerprint and randomart, which are both unimportant to anyone who is not a cryptography nerd.
Note
When you run ssh-keygen, you can set the type of cryptographic key with -t.
Many security experts recommend Ed25519, which is the default on most
computers (you can set -t ed25519 to be sure). The original RSA
algorithm (-t rsa) also remains popular. Some servers require specific
key types.
After creating a key, you can send the public key to a server administrator so that they can associate it with your new account. You can also go through this process in the unfortunate event that you somehow lose your private key.
Note
If you’re affiliated with UC Davis and use HiPPO to request a high-performance computing cluster account, you’ll be asked to submit your public key as part of your request.
If your server administrator uses a web form for new account requests, you might need to copy the contents of your public key into the form. There are several different ways to copy a file’s contents to the clipboard, depending on your operating system:
You can use clip to copy the contents of a file to the clipboard:
clip < ~/.ssh/new_key.pub
You can use pbcopy to copy the contents of a file to the clipboard:
pbcopy < ~/.ssh/new_key.pub
You can use xsel to copy the contents of a file to the clipboard:
xsel --clipboard < ~/.ssh/new_key.pub
Alternatively, you can use xclip:
xclip -selection clipboard < ~/.ssh/new_key.pub
Some Linux distributions do not include either command by default, but they can generally be installed through the package manager.
These commands are all for convenience. If none of them work for you, you can
instead open the public key file with a text editor (such as nano or vi),
select all of the contents, and copy the selection.
1.4.2.2. Uploading SSH Keys#
If you already have an account on a server and want to switch from password authentication to SSH key authentication, or just want to add a new SSH key, it’s usually possible to do so without help from the server’s administrators.
To upload an SSH key to a server with which you are already able to authenticate, open a terminal on your local computer and run:
ssh-copy-id <account name>@<server name> -i <your_key>
where <your_key> is the path to the public key file you want to upload.
1.5. Configuring SSH#
You can configure SSH and the ssh command to fit your specific needs, so that
it’s simpler and easier to use. For instance, you can set names and default
arguments for servers you access frequently, so that you don’t have to remember
and type long ssh commands. Knowing how to configure SSH is also important
because configuration problems can prevent you from accessing servers or even
from using the ssh command.
By convention, SSH configuration files are stored in a hidden .ssh/ directory
in your home directory (~). The .ssh/ directory is also the default
location for key files, both public and private. The subsequent sections
explain what specific files in the directory do and how to make sure the
directory is kept secure.
1.5.1. The config File#
~/.ssh/config contains local configuration data for SSH programs like ssh.
The most useful settings in that file are per-server settings that associate
account names, and potentially SSH key files, with server names, to simplify
managing different user identities on different servers.
For example, imagine that you have accounts on two different servers: an
account named testuser on a server named testserver, using an SSH key for
authentication, and an account named m34754_a2 on a server named
anotherserver, also using an SSH key for authentication, but using a
different key pair than for server testserver (while using different SSH keys
for different servers does not actually increase security, there might still be
other reasons for doing so). Then you would have to use the following two
commands to log into the two servers, respectively:
ssh testuser@testserver
and
ssh -i ~/.ssh/anotherserver_rsa m34754_a2@anotherserver
The -i <key file name> option for ssh selects a specific SSH key other than
the default id_rsa. To avoid typing this every time, you could add the
following text to your ~/.ssh/config file using a text editor like vim:
Host testserver
User testuser
IdentityFile ~/.ssh/id_rsa
Host anotherserver
User m34754_a2
IdentityFile ~/.ssh/anotherserver_rsa
The
Hostkeyword tells SSH programs that the following settings, up until the nextHostkeyword, only apply to servers whose names match the pattern after theHostkeyword.The
Userkeyword specifies the account name to use when connecting to the matching server(s).The
IdentityFilekeyword specifies the name of the private SSH key file to use for authentication when connecting to the matching server(s).
With these lines in your ~/.ssh/config file, you would then be able to
connect to those two servers with the (much) shorter following commands:
ssh testserver
and
ssh anotherserver
The full set of available configuration options is described in ssh-config’s
documentation (man ssh_config).
1.5.2. The known_hosts File#
~/.ssh/known_hosts contains the public SSH keys of servers to which you
have connected in the past (not your own keys). These are stored to prevent
“man-in-the-middle” attacks, where a third party attempts to intercept SSH
connection traffic by pretending to be a server to which you want to connect,
accepting incoming SSH connections from you, and then transparently forwarding
those connections and their content to the actual server. While SSH connections
are secure between the two ends of a connection, this setup would allow a third
party to see unencrypted data traveling between you and the intended remote
server because there are now two encrypted connections: one between you and
the man-in-the-middle, and one between the man-in-the-middle and the remote
server to which you actually wanted to connect.
Server keys can prevent this type of attack. In the same way that a server can verify your identity via your public SSH key, you, or rather the SSH client on your local computer, can verify a server’s identity via that server’s public SSH key.
When you connect to a server to which you have connected in the past, the
ssh program compares that server’s public SSH key to the one in your
known_hosts file. If the keys do not match, ssh refuses to establish the
connection, because it can not prove that the server is the same one to which
it connected before, meaning that the server is potentially being impersonated
by a malicious third party.
In rare circumstances, servers may legitimately change their SSH keys. If ssh
indicates a server key mismatch, the secure approach is to directly contact the
administrators of that server to confirm that the key was legitimately changed,
and, if that is the case, ask to receive a copy of the server’s new public SSH
key. You will then have to manually replace the server’s old SSH key with its
new one in yourknown_hosts file by opening that file with a text editor such
as vim, finding the old server key (ssh will print the number of the line
containing the mismatching key), replacing it with the new key, and then saving
the edited file.
But what happens when a new user tries to connect to a server for the first
time? At that point, the known_hosts file does not yet know that server’s key,
and has nothing to compare against. The default behavior of ssh is to silently
accept keys from new servers and add them to the known_hosts file. On highly
security-aware servers, this adds another step to the sign-up procedure for new
users. After setting up a new user’s account, the server administrator will
inform the new user not only of their new account name, but also of the server’s
public SSH key. The user will then manually add that key to their known_hosts
file before connecting to the server for the first time, and thus prevent a
potential man-in-the-middle attack even on the first connection.
1.5.3. Permissions#
Because ~/.ssh/ contains some data that must remain private to you, such as
private SSH keys, many SSH programs will refuse to operate if this directory or
its contents have incorrect sets of permissions (access privileges).
In Unix-like operating systems like Linux, there are three separate sets of permissions on every file or directory:
User (u): These permissions apply to the single user who owns a file or directory.
Group (g): These permissions apply to users who belong to the group associated with the file or directory.
Other (o): These permissions apply to all users who fall into neither of the previous two groups.
Inside each of these groups, there are three permissions:
Read (r): The user can read the contents of a file or directory.
Write (w): The user can change the contents of a file, or add/move/remove files to/from a directory.
Execute (x): The user can execute, i.e., run, a program or script file, or enter into a directory.
The current permissions of a file or directory can be queried by running ls -l on that file or directory, and are displayed like this:
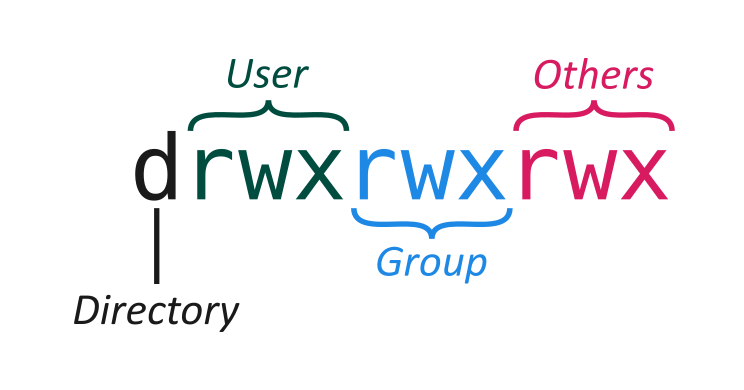
Fig. 1.2 Permissions as displayed by the ls -l command. The first character indicates
whether or not this is a directory. Each group of 3 characters after that
indicates the read (r), write (w), and execute (x) permissions for you
(the user), members of the file’s or directory’s associated group, and all
other users. A dash - instead of a letter indicates lack of permission.#
For example:
-rwxr-x---for a regular file, where the first threerwxcharacters denote the user permissions, followed by three characters for the group permissions, followed by three characters for the other users’ permissions. Dashes indicate that a permission is missing. This example shows an executable file (program or script) that can be read, written, and executed by the user owning it; read and executed by users in the file’s associated group, and cannot be accessed at all by other users.drwxr-xr-xfor a directory. The initialdindicates that this is a directory, and the rest of the characters have the same meaning as for files. This example shows a directory whose contents can be read and changed, and that can be entered, by its owner, whose contents can be read but not changed, and that can be entered, by users in the directory’s group, and that is inaccessible to all other users.
These are the recommended permissions for the .ssh/ directory and its files:
Name |
Permissions |
|---|---|
|
|
Public key files ( |
|
Private key files |
|
|
|
|
|
All other files |
|
You can change the permissions on a file or directory with the chmod command
(short for “change file mode bits”). The command typically takes two arguments:
a mode string and a path to a directory or file to change.
The mode string controls how the permissions are changed, and has three parts:
Who:
ufor user,gfor group,ofor others, or some combination of these.How:
+to grant permission,-to revoke permission, or=to set permission equal to.Which permission:
rfor read,wfor write,xfor execute, or some combination of these.
So u+rw grants read and write permission for the user, and ugo-x revokes
execute permission from the user, the group, and everyone else. You can specify
multiple mode strings by separating them with commas (but no spaces).
For example, to set correct permissions on ~/.ssh/config:
chmod u=rw,go= ~/.ssh/config
And to set the correct permissions on ~/.ssh/:
chmod u=rwx,go= ~/.ssh
Caution
The ssh command will raise an error if you set incorrect permissions on the
.ssh/ directory, the config file, or the known_hosts file. The error
message looks something like this:
Bad owner or permissions on ~/.ssh/config
To fix this, check and correct the permissions. Then try running the ssh
command again.
1.6. Moving Data between a Local Computer, the Internet, and a Server#
An established SSH connection between your local computer and a remote server sends your keystrokes to the remote server, and sends the output of the shell running on the remote server back to your local computer, but it does not otherwise send data or code between those two ends. Therefore, uploading data from your local computer to a server, downloading data from the Internet to a server, or downloading data from a server to your local computer require additional tools.
1.6.1. Download Files from the Internet#
The first pair of commands, to download data from the Internet to any
computer, including your local computer and a server to which you are connected
via SSH, are wget and curl. Both of these commands do basically the same
thing, but for historical reasons, one or the other (or sometimes both) may be
installed on any specific computer. It is therefore important to know the
basics of using both of them.
1.6.2. wget#
wget (as in “web get”) is the simpler of the two commands. It can be used to
download one or more files, entire directories, or even entire directory
hierarchies from the Internet, via multiple protocols including HTTP and HTTPS.
Its most common use is to download files from web servers. Usually, you would
download a file from a web server via a web browser, by right-clicking on a
hyperlink in a web page and selecting “Save Link As…” from the menu that pops
up in response. In its simplest form, wget does the same, but from the
command line and without requiring further actions from you. To download the
file referenced by a given URL, you simply pass that URL on wget’s command
line:
me@mypc$ wget https://www.google.com
--2023-12-05 11:17:29-- https://www.google.com/
Resolving www.google.com (www.google.com)... 142.251.46.196, 2607:f8b0:4005:812::2004
Connecting to www.google.com (www.google.com)|142.251.46.196|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: ‘index.html’
index.html [ <=> ] 18.89K --.-KB/s in 0.001s
2023-12-05 11:17:30 (22.5 MB/s) - ‘index.html’ saved [19348]
me@mypc$ ls -l index.html
-rw-r--r--. 1 me me 19348 Dec 5 11:17 index.html
The above command will download the entirety of the Internet and store it on your local computer.
No, just kidding, it will download index.html, the HTML file that renders
Google’s front page, the one that is shown when visiting the
https://www.google.com/ URL with a web browser. It’s a surprisingly small
file, and fun to look at.
In the same way, wget can download files referenced by any other URLs. A
common practical way to do this is to visit the web site hosting a desired file
using a web browser, to locate a hyperlink for the file you want to download,
then to right-click on that hyperlink and select “Copy Link” in the pop-up
menu, and finally to paste the copied link into wget’s command line. And
because wget is command line-based, this can be used to download a file to a
server by executing wget on that server via an SSH connection:
me@mypc$ ssh testuser@testserver
Last login: Tue Dec 5 10:32:57 2023 from 192.168.2.109
testuser@testserver$ wget https://www.nasa.gov/wp-content/uploads/2023/03/135918main_bm1_high.jpg
--2023-12-05 11:27:28-- https://www.nasa.gov/wp-content/uploads/2023/03/135918main_bm1_high.jpg
Resolving www.nasa.gov (www.nasa.gov)... 192.0.66.108, 2a04:fa87:fffd::c000:426c
Connecting to www.nasa.gov (www.nasa.gov)|192.0.66.108|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 195439 (191K) [image/jpeg]
Saving to: ‘135918main_bm1_high.jpg’
135918main_bm1_high.jpg 100%[===============================>] 190.86K --.-KB/s in 0.007s
2023-12-05 11:27:28 (27.9 MB/s) - ‘135918main_bm1_high.jpg’ saved [195439/195439]
When downloading a URL, wget will store the file referenced by that URL in
the current directory from which wget was run, using the same file name as
the file on the server (in the above example, 135918main_bm1_high.jpg). This
is seldom useful, because the names of files on web servers are commonly
auto-generated and non-descriptive. Instead, you can specify a desired location
and name for the downloaded file via the -O <file name> (that is uppercase O
for “output file name”) command line option for wget. The -O <file name>
option must appear before the URL of the file to be downloaded. While at it,
you can also reduce the amount of extra information wget prints while
downloading via the -q (for “quiet”) command line option:
testuser@testserver$ wget -q -O BlueMarble1972.jpg https://www.nasa.gov/wp-content/uploads/2023/03/135918main_bm1_high.jpg
testuser@testserver$ ls -l BlueMarble.jpg
-rw-rw-r-- 1 testuser testuser 195439 Apr 6 2023 BlueMarble1972.jpg
True to form for a Unix utility, wget will print absolutely nothing in quiet
mode unless there is an error. The output file name specified via -O can
contain absolute or relative paths, such as Images/BlueMarble1972.jpg, or
/home/testuser/Images/BlueMarble1972.jpg or ~/Images/BlueMarble1972.jpg for
short.
wget can download multiple files in one go by using wildcards like * in the
URL:
wget -q https://www.nasa.gov/wp-content/uploads/2023/03/*.jpg
which will download all JPEG image files (or, more accurately, all files whose
names end in .jpg) in the March 2023 upload section of NASA’s main web site
(which is probably not a good idea!), or by referencing a directory instead of a
file, which will download all files in that directory:
wget -q https://www.nasa.gov/wp-content/uploads/2023/03/
(also not a good idea!). wget can even download an entire directory
hierarchy via the -r (for “recursive”) command line option:
wget -q -r https://www.nasa.gov/wp-content/uploads/
which will download all media files NASA ever uploaded to their web site (now
this is an outright terrible idea!). When downloading a directory or directory
hierarchy, wget will recreate the server’s directory structure starting from
the server name. In the above example, it will create a new directory
www.nasa.gov in the current directory, a directory wp-content inside of
that, uploads inside of that, etc. Thus, the 1972 Blue Marble image that was
downloaded in an earlier example would now appear as
www.nasa.gov/wp-content/uploads/2023/03/135918main_bm1_high.jpg.
By default, wget stores downloaded files or directories in the current
directory. This can be changed via the -P <root directory> option (for
“directory prefix”). If given, directories and files will be created underneath
the given directory, which can be identified by an absolute or relative path:
me@mypc$ wget -q -P ~/Images https://www.nasa.gov/wp-content/uploads/2023/03/135918main_bm1_high.jpg
will store the downloaded image in the user’s Images directory, under the name
135918main_bm1_high.jpg.
1.6.3. curl#
curl (as in “copy URL”) is the other command line utility that can download
files from the Internet. curl supports even more remote file access protocols
than wget, and, according to its documentation (man curl), “[its] number of
features will make your head spin.”
In its simplest invocation, curl will download the file referenced by a given
URL and print its contents to the terminal. Instead of printing to the
terminal, which is often not very useful, curl’s output can be redirected into
a file via the output operator >, or piped as input into another program via
the pipe operator |:
testuser@testserver$ curl https://www.nasa.gov/wp-content/uploads/2023/03/135918main_bm1_high.jpg > BlueMarble1972.jpg
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 19206 0 19206 0 0 137k 0 --:--:-- --:--:-- --:--:-- 137k
In the Unix world, data or programs are often made available for download as
gzip-compressed tar (for “tape archive”) files, commonly known as
“tarballs.” A neat trick to download such a tarball from a web server and
decompress and unpack it on the fly without storing the tarball itself on your
local hard drive is to download it via curl and pipe it directly into the
tar program for decompression and unpacking:
me@mypc$ curl http://testserver/DataArchive.tar.gz | tar xfz -
which will recreate the complete directory hierarchy that was packed into the
tarball inside the current directory. Using wget, the same command would be:
me@mypc$ wget -O - http://testserver/DataArchive.tar.gz | tar xfz -
(-O - instructs wget to print the downloaded file to the terminal, mirroring
the default behavior of curl).
Instead of redirecting output to a file via >, curl can also be instructed
to write to a file directly by using the -o or -O command line options. -o
(lowercase o) needs a file name, while -O (uppercase O) uses the file
name component of the given URL. In other words, curl -O <URL> aligns with
the default behavior of wget <URL>, and curl -o <file name> <URL> aligns
with wget -O <file name> <URL>. There is one big difference, however: unlike
wget, curl’s -o option only accepts file names and does not support
paths. To create the named file in a directory other than the current
directory, one has to add the --output-dir (notice two dashes!) option. This
behavior means that it is often easier to ignore the -o option, and use
output redirection instead.
Like wget, curl will print continuous status updates while downloading, and
write download statistics when done. Also like wget, these updates can be
disabled, but unlike wget, the associated command line option is -s (for
“silent”), and curl in silent mode will not even print a message if there is
an error while downloading a file, unless error messages are re-enabled by
adding -S (uppercase S, for “not quite so silent, thankyouverymuch”) after
-s.
1.6.4. Transfer Files between a Local Computer & a Server#
Unlike wget and curl, the next pair of commands can be used to transfer
files between your local computer and a remote server. The first, scp, is
non-interactive and behaves similarly to the standard Unix cp command, but
with the added ability to access files on remote servers. The second command,
sftp, is an interactive terminal application like vim, in the sense that it
opens a custom “shell” in which you can run commands that allow local and
remote file operations and transfers. While scp can only transfer files
between computers, sftp additionally supports file management operations like
creating and removing directories, moving, renaming, and deleting files, etc.
1.6.5. scp#
scp (as in “secure copy”) is straightforward to use. Just like cp, it takes
the name of a source file, and the name of a destination file or the name of a
directory into which to copy the source file. Unlike cp, the source file
and/or destination file or directory can exist on different computers. Remote
files or directories are indicated by prefixing a regular path with the name of
a server followed by a colon, as in <server name>:<path>, which will then
refer to the path of the given name on the indicated remote computer.
Additionally, the server name can be prefixed with an account name followed by
an “@” sign, as in <account name>@<server name>:<path>. For example,
me@mypc$ scp BlueMarble1972.jpg testuser@testserver:Images/
will copy a BlueMarble1972.jpg file from the current directory on your local
computer into the Images directory in the testuser account on the
testserver server. Remote paths are relative to the remote user’s home
directory, unless they start with a / (forward slash), which indicates that
they are relative to the remote server’s root directory. When a local or remote
destination path identifies a directory, the destination file will be created in
that destination directory with the same name as the source file. The command
me@mypc$ scp testuser@testserver:Images/BlueMarble1972.jpg .
will do the exact opposite, copying BlueMarble1972.jpg from the Images
directory under the testuser account’s home directory on server testserver
to the current directory on your local computer. The . at the end of the
command line is Unix shorthand for the current directory, and thus tells scp
to give the destination file the same name as the source file, and to store it
in the current directory on your local computer. Equivalently, you could have
specified the name of the destination file explicitly:
me@mypc$ scp testuser@testserver:Images/BlueMarble1972.jpg BlueMarble1972.jpg
scp also supports wildcards like * in source paths to copy more than one
file at a time:
me@mypc$ scp testuser@testserver:Images/*.jpeg Images/
will copy all JPEG files (or, rather, files whose names end in .jpeg)
contained in testuser’s Images directory on server testserver to the
Images directory on the local computer.
Like cp, scp supports recursive copying of entire directory hierarchies
using the -r (lowercase r for “recursive”) option (note that the equivalent
option for cp is -R with an uppercase R). When used with -r, both the
source and destination paths specified on scp’s command line must be
directories.
1.6.6. sftp#
sftp (as in “secure file transfer protocol”) is an interactive terminal
application to transfer files between a local computer and a server, and to
perform file management (creating/deleting directories,
moving/renaming/deleting files, etc.) on both ends of an SSH connection. sftp
is invoked similarly to ssh:
sftp <account name>@<server name>
The above command instructs sftp to connect to server <server name> using
account <account name>. Being an interactive application, sftp will then
enter a command loop where it prints an sftp> prompt, waits for you to enter
a command, executes that command, and repeats. The bye, exit, or quit
commands tell sftp to close the connection to the server, exit the program,
and return you back to your local shell.
1.6.7. Current Directories#
Because sftp’s purpose is file transfer and management, it has the same
concept of a current directory or working directory as a regular shell, to
relieve you from always having to enter absolute paths to identify the file(s)
on which you want to operate. Unlike a regular shell, however, sftp has two
current directories: one on your local computer, and one on the server.
Consequently, the commands to query or alter those current directories also
come in pairs, where the command referring to the local current directory has
an “l” (lowercase l for “local”) prefix, and the other one works exactly like
the shell command of the same name:
pwdandlpwd(for “(local) print working directory”) print the paths of the remote or local current directory, respectively.cd <path>andlcd <path>(for “(local) change directory”) set the path of the remote or local current directory to the given path, respectively.ls <path>andlls <path>(for “(local) list”) list the contents of the given remote or local path, respectively. These commands work the same, and have most of the same options as, a regular shell’slscommand.
Any local or remote path used by any sftp commands is relative to the local
or remote current directory, respectively, unless the path begins with a /
(forward slash), in which case it is relative to the root of the local or
remote file system, respectively. As in a regular shell, . (single dot)
refers to a directory itself, and .. (two dots) refers to a directory’s
parent. Unfortunately, the ~ shortcut for an account’s home directory does
not work in remote paths, and the remote home directory must be spelled out as
/home/<account name>.
The following is an example sftp session using the above commands:
me@mypc$ sftp testuser@testserver
Connected to testserver.
sftp> lpwd
Local working directory: /home/me
sftp> lls
Documents Downloads Images src ToDoList.txt
sftp> lls -la
drwx------ 19 me me 4096 Dec 7 09:45 .
drwxr-xr-x 6 root root 4096 Nov 4 2021 ..
-rw-r--r-- 1 me me 1164 Nov 12 2021 .bashrc
drwx------ 2 me me 4096 Oct 20 2022 .ssh
drwxr-xr-x 3 me me 4096 Oct 20 2022 Documents
drwxr-xr-x 3 me me 4096 Oct 20 2022 Downloads
drwxr-xr-x 2 me me 16384 Dec 6 2023 Images
drwxr-xr-x 3 me me 8192 Mar 16 2023 src
-rw------- 1 me me 2158216 Dec 7 09:31 ToDoList.txt
sftp> pwd
Remote working directory: /home/testuser
sftp> ls -l
drwxr-xr-x 3 testuser testuser 8192 Dec 6 2023 Images
-rw------- 1 testuser testuser 2158139 Dec 7 09:21 ToDoList.txt
drwxr-xr-x 3 testuser testuser 8192 Mar 17 2023 src
sftp> cd Images
sftp> pwd
Remote working directory: /home/testuser/Images
sftp> ls -l
-rw-r--r-- 1 testuser testuser 195439 Apr 6 2023 BlueMarble1972.jpg
sftp> cd ..
sftp> pwd
Remote working directory: /home/testuser
sftp> exit
me@mypc$
When sftp starts, the local current directory is initialized to your local
shell’s current directory, and the remote current directory is set to the home
directory of the given account on the server. It is also possible to start with
a different remote current directory by appending that directory’s path to the
server name given on sftp’s command line, separated by a colon:
sftp <account name>@<server name>:<path>
1.6.8. Uploading & Downloading Files#
The get <remote path> [local path] command downloads one or more files from
the remote server to the local computer. The <remote path> argument
identifies the remote file(s) to download. If <remote path> refers to a
directory, all files in that directory will be downloaded. If <remote path>
contains wildcards such as *, all files whose names match the given pattern
will be downloaded.
The optional [local path] argument specifies the path to which to download
the remote file(s). If it is omitted, get will operate as if [local path]
was given as ., i.e., the current local directory. If [local path] refers to
a directory, the remote files will be downloaded to that directory retaining
their remote names. If <remote path> selects more than one file (by being a
directory or containing a wildcard), [local path] must refer to a directory.
Example of downloading a file using the get command:
me@mypc$ sftp testuser@testserver
Connected to testserver.
sftp> get Images/BlueMarble1972.jpg Images/
Fetching Images/BlueMarble1972.jpg to Images/BlueMarble1972.jpg
BlueMarble1972.jpg 100% 195439 266.3KB/s 00:00
sftp> lls -l Images
-rw-r--r-- 1 me me 195439 Dec 7 09:57 BlueMarble1972.jpg
sftp> exit
me@mypc$
Common get options:
-R(uppercase R for “recursive”): Downloads an entire directory hierarchy starting from the given remote path. The local path, if provided, must be a directory.-a(for “append”): Attempts to resume a download that was previously interrupted.sftpwill use the size of the existing local file to skip downloading the initial portion of that size of the remote file, but it will not check whether the existing local file differs from that initial portion. In other words, if the local and/or remote file were changed since the interrupted download, the two files will not be identical after the download completes, which will typically result in an unusable corrupted file.-p(for “permissions”):sftpwill also copy the full set of file permissions and the access time of the remote file. Without this option, the new local file’s access time will be set to the current local time, and its permissions will be set to your local account’s default permissions.
The put <local path> [remote path] command uploads one or more files from the
local computer to the remote server. The <local path> argument
identifies the local file(s) to upload. If <local path> refers to a
directory, all files in that directory will be uploaded. If <local path>
contains wildcards such as *, all files whose names match the given pattern
will be uploaded.
The optional [remote path] argument specifies the path to which to upload
the local file(s). If it is omitted, put will operate as if [remote path]
was given as ., i.e., the current local directory. If [remote path] refers
to a directory, the local files will be uploaded to that directory retaining
their local names. If <local path> selects more than one file (by being a
directory or containing a wildcard), [remote path] must refer to a
directory.
Example of uploading a file using the put command:
me@mypc$ sftp testuser@testserver
Connected to testserver.
sftp> put ToDoList.txt
Uploading ToDoList.txt to /home/testuser/ToDoList.txt
ToDoList.txt 100% 2108KB 4.0MB/s 00:00
sftp>ls -l
drwxr-xr-x 3 testuser testuser 4096 Dec 6 2023 Images
-rw------- 1 testuser testuser 2158216 Dec 7 11:38 ToDoList.txt
drwxr-xr-x 3 testuser testuser 4096 Mar 17 2023 src
sftp> exit
me@mypc$
Common put options:
-R(uppercase R for “recursive”): Uploads an entire directory hierarchy starting from the given local path. The remote path, if provided, must be a directory.-a(for “append”): Attempts to resume an upload that was previously interrupted.sftpwill use the size of the existing remote file to skip uploading the initial portion of that size of the local file, but it will not check whether the existing remote file differs from that initial portion. In other words, if the remote and/or local file were changed since the interrupted upload, the two files will not be identical after the upload completes, which will typically result in an unusable corrupted file.-p(for “permissions”):sftpwill also copy the full set of file permissions and the access time of the local file. Without this option, the new remote file’s access time will be set to the current remote time, and its permissions will be set to the remote account’s default permissions.
1.6.9. Remote File Management#
Unlike scp, sftp supports remote file management in addition to file
up-/downloads, via a set of commands that mimic the behavior of regular shell
file management commands. sftp’s most common remote file management commands
are:
rename <from path> <to path>renames the file or directory referred to by<from path>to<to path>. If<from path>and<to path>are in different directories, the file or directory will be moved from the “from” to the “to” directory.copy <from path> <to path>copies the file or directory referred to by<from path>to<to path>. If<to path>refers to a directory, the file or directory will be copied into that directory while retaining its original file name.rm <path>removes the file referred to by<path>.mkdir <path>creates a new directory at the given<path>.rmdir <path>removes the directory referred to by the given<path>. The directory must be empty.chmod <mode> <path>changes the permissions of the file or directory referred to by<path>to the given<mode>in octal notation. Please refer tochmod’s documentation (man chmod) for details on octal notation.
For convenience, sftp offers a local counterpart to the mkdir command, to
create a new directory on the local computer: lmkdir <path>
1.7. The POSIX Directory Structure and Permissions#
As servers are typically Unix machines, the layout of their filesystems typically follow the POSIX Filesystem Hierarchy Standard. This means the file system is generally split between system directories, user home directories, and “other” directories. System directories contain programs and data shared by all users on the server, while user home directories contain programs and data private to each user. “Other” directories can contain a mix of these two.
1.7.1. System Directories#
As system directories contain data and programs that are shared by all users,
their contents are typically readable by all users, but can only be modified by
the superuser (root). In other words, their permissions are typically
drwxr-xr-x, and the permissions of the files contained within them are
typically -rw-r--r-- for data files and -rwxr-xr-x for program and library
files. The most relevant system directories are:
/binand/sbincontain programs that are essential for operating a Unix system, such asls,cat,cp, etc./bincontains user-level programs;/sbincontains programs that are only meant to be used by administrators/liband/lib<arch>(e.g.,/lib64) contain library files (libraries are bundles of common code shared by multiple programs) essential to programs in/binand/sbin/usris a second-level hierarchy containing the majority of utilities and applications installed on a Unix system/usr/bin,/usr/sbin,/usr/lib,/usr/lib<arch>contain user-level programs, administrator-level programs, and libraries shared by those programs, respectively/usr/includecontains include files that are used by developers to create and build applications on the server, primarily using the libraries in/usr/liband/usr/lib<arch>/usr/localis a third-level hierarchy containing utilities and applications that have been built specifically for one server, i.e., are not part of the “standard” operating system. It in turn containsbin,sbin,lib,lib<arch>,include, etc. directories/etccontains host-specific system-wide configuration files. According to Unix lore, “etc” does not stand for “et cetera,” and is pronounced “etsy” or sometimes “ee-tee-see”/optcontains optional software packages accessible to all users on a system
1.7.2. User Home Directories#
Users’ home directories appear inside the /home hierarchy, and are named by
each user’s account name, such as /home/me or /home/testuser. As home
directories are supposed to be private to each user, they can typically be read
and written by the user owning them, can be read but not written by the user’s
group, and are neither readable nor writable by other users. In short, their
permissions are typically drwxr-x---.
Sometimes a user might accidentally misconfigure their home directory’s permissions to allow read or even write access by other users. Exploiting such a mistake by snooping in other user’s home directories is considered a serious invasion of privacy, and changing files in other users’ home directories is considered a capital offense and will most probably result in a lifetime ban from the server.
1.7.3. Other Directories#
Other directories are a mixed bag. The most relevant one is /tmp, which holds
temporary files that are not meant to exist beyond the lifetime of whichever
program created them. Many programs that need to create temporary files to
operate create them here, and as such, the /tmp directory is typically
readable and writable by all users. The files contained within it, on the other
hand, are owned by the users who created them, respectively, and are typically
readable and writable by those users, and neither readable nor writable by
other users. A server’s operating system or administrators might start deleting
files in /tmp without warning if the server’s file system starts to run out
of space – or for any other reason, really.