4. Case-by-case Practices#
Attention
This chapter is still a work-in-progress and will be completed sometime in Fall Quarter 2024. Check back when you’ve got some experience with research computing and are ready to learn more.
This chapter covers case-by-case practices for reproducibility. Many of these practices require substantial effort to adopt or require specific technical knowledge. They can be important and even essential for certain kinds of projects, but we feel they aren’t broadly applicable in the ways that core and case-by-case core practices are. DataLab occasionally adopts these practices. Read this chapter when you feel like you’ve mastered the practices in the previous chapters and want to learn even more.
4.1. Documentation#
4.1.1. Make Workflow Diagrams#
See also
See DataLab’s README, Write Me! workshop reader for suggestions about how to create workflow diagrams.
4.1.2. Use Issue Tracking#
4.1.3. Make a Data Management Plan#
See also
See DataLab’s Data Management Plan toolkit for instructions about how to make a data management plan.
4.2. Artifact Preservation#
4.2.1. Log Output#
See also
If you’re using R, see DataLab’s Intermediate R: Outputs, Errors, and Bugs workshop reader for a brief overview of a how to manage log files in R.
If you’re using Python, see DataLab’s Intermediate Python: Squashing Bugs with Python’s Debugging Tools workshop reader for a brief overview of how to manage log files in Python.
4.3. Project Organization#
4.3.1. Make a Package#
4.4. Workflow Automation#
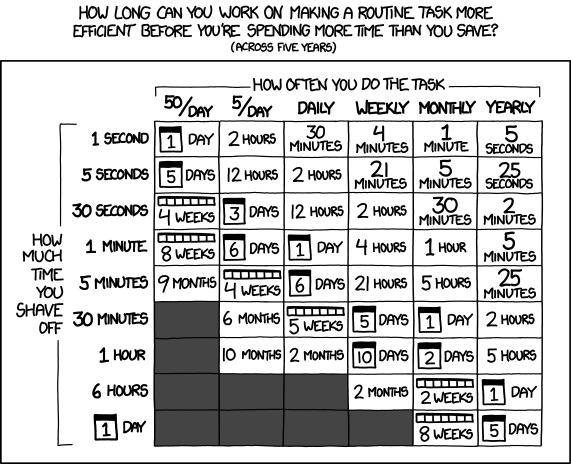
Fig. 4.1 “Is It Worth the Time?” from “xkcd” by Randall Munroe (license).#
4.4.1. Use a Build System#
See also
See DataLab’s and DIB Lab’s Automating Your Analyses with the Snakemake Workflow System workshop reader for a technical introduction to snakemake.